Duncan Watts and CSSLab’s New Media Bias Detector
Researchers at the Computational Social Science Lab have developed the Media Bias Detector, which uses artificial intelligence to analyze news articles, examining factors like tone, partisan lean, and fact selection.

The 2024 U.S. presidential debates kicked off June 27, with President Joe Biden and former President Donald Trump sharing the stage for the first time in four years. Duncan Watts, a computational social scientist from the University of Pennsylvania, considers this an ideal moment to test a tool his lab has been developing during the last six months: the Media Bias Detector.
“The debates offer a real-time, high-stakes environment to observe and analyze how media outlets present and potentially skew the same event,” says Watts, a Penn Integrates Knowledge Professor with appointments in the Annenberg School for Communication, School of Engineering and Applied Science, and Wharton School. “We wanted to equip regular people with a powerful, useful resource to better understand how major events, like this election, are being reported on.”
The Media Bias Detector uses artificial intelligence to analyze articles from major news publishers, categorizing them by topic, detecting events, and examining factors like tone, partisan lean, and fact selection.

Watts and a few members of his team at the Computational Social Science Lab (CSSLab) discuss their motivations for creating the Media Bias Detector, rationale for launching this tool ahead of the presidential debates, and key insights from the project.
What Sparked the Debate Around Media Narratives
Watts says the idea of the Detector has been brewing for years, long before he joined Penn in 2019, when he’d read articles on topics he happened to have expertise in and started to realize that “some of this is just complete hogwash,” he says.
“But that really got me thinking: What about the stuff that I don’t know about? Is that all just fine, and the only problematic information out there is just the stuff I happen to know about?’”

Watts also cites anecdotes from early in his career when he’d talk to reporters who clearly knew what they wanted to say before reporting the piece. “I’d offer a perspective that didn’t fit their preselected narrative, so they would just not quote me, which was kind of frustrating,” he says. “So, I think I’ve always had some concerns about how media can distort the world through the lens of presenting a particular set of facts in a particular order.”
But, as with many people, Watts says, “those concerns grew following the coverage of the 2016 election. It made me think that media bias might actually be a big problem, not just a nuisance in my little corner of the information landscape.”
To that end, Watts started investigating how some of the ways information related to the election and other global events circa 2016 were covered and began to see that media narratives about “misinformation,” “fake news,” and “echo chambers’ were in and of themselves misleading and in some instances “overblown.”
In the lead-up to the 2016 presidential election, Watts says, many people maligned the echo chambers they believed they saw taking over social media. People with like-minded friends were all sharing content online with the same political bent, amplifying a singular set of messages and leading to greater polarization overall.
However, according to research led by Watts, just 4% of Americans actually fell into such echo chambers online. But the number for television was much higher, with 17% of people in the U.S. consuming TV news from only partisan left- or right-leaning sources, news diets they tend to maintain month over month.
These experiences led Watts to believe there was a problem with how media presents information, but it seemed out of reach to build something that could consolidate news articles in real-time with a high degree of granularity and let people know where the biases were.
“The methods that could do this sort of classification at scale didn’t work sufficiently well until the latest generation of large language models (LLMs) arrived towards the end of 2022,” Watts says. “The popularization of OpenAI’s ChatGPT truly changed the game and made it possible for our team to design the Detector around OpenAI’s GPT infrastructure.”
A Bit of the Nuts and Bolts
Playing crucial roles in leveraging these LLMs to build the Detector were Samar Haider, a fourth-year Ph.D. student in the School of Engineering and Applied Science; Amir Tohidi, a postdoctoral researcher in the CSSLab; and Yuxuan Zhang, the lab’s data scientist.
Haider, who focuses on the intersection of natural language processing and computational social science, explains that the team “gives GPT the article and asks it to say which of a list of topics it belongs to and, for events, to compare the meaning or semantic similarity of the text.”
To manage this massive influx of data, the team developed its own pipeline.
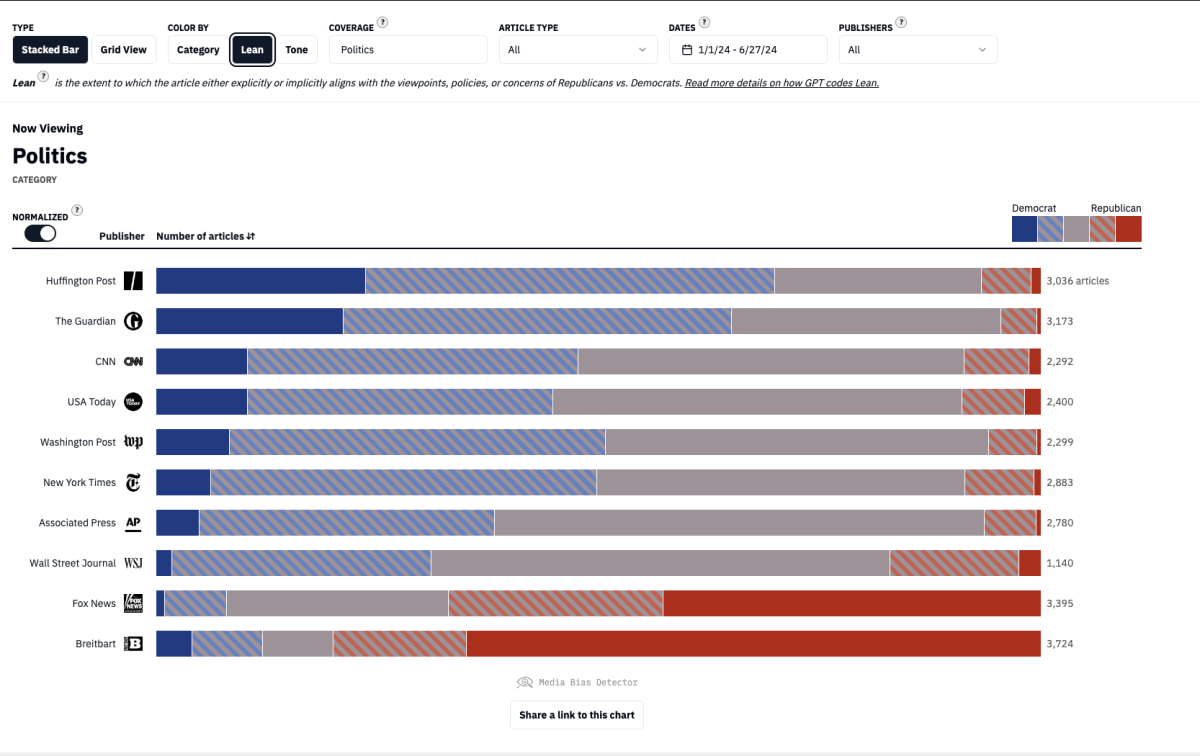
“We then break the process into two parts: categorizing articles by topics using GPT and clustering articles into events using a sliding window approach to compare their text,” Tohidi says. “This method allows the Detector to not only label articles accurately but also to detect emerging topics and events in real time.”
However, Tohidi says human judgment remains a critical component of their system. Every week, research assistants read a subset of articles to verify GPT’s labels, ensuring they maintain high accuracy and can adjust for any errors they may encounter along the way.
“We’re currently scraping 10 major news websites every few hours and pulling the top 10 articles, which is a few hundred articles per publisher per day, and processing all of that data. We’re planning to increase it to the top 30 articles for our future versions to better represent media coverage. It’s a massive task,” Zhang says, “but it’s essential for keeping the tool up to date and reliable.”
A Changing View on the Media Landscape
Haider notes that in building the tool he has come to appreciate the power of biases in language, such as when the same set of facts can convey different messages depending on how writers use them.
“It’s just incredibly fascinating to see how these subtle differences in the way you can report on an event, like how you put sentences together or the words you can use, can lead to changes for the reader that journalists might not realize because of their own biases,” Haider says. “It’s not just about detecting bias but understanding how these subtle cues can influence the reader’s perception.”
Watts says that, while the current version of the Detector doesn’t have this feature integrated yet, he, too, has come to see how much of an impact small decisions in reporting can have.
He notes that in watching how this component can take in the facts and generate articles, some with a positive spin and others negative, “it is a little spooky to see how much you can alter things without lying. But it’s also potentially a really cool feature that can write differently biased synthetic articles about events on the fly.”
Watts says that there is no shortage of people who love to criticize journalists and that he isn’t trying to add fuel to the fire or create an AI tool to replace reporters. Rather, he and the CSSLab have created the Media Bias Detector in recognition of the importance of journalism.
“Journalists are crucial, as the fourth estate,” Watts says. “We want this tool to hold up a data-driven mirror to current journalistic practices, both good and bad, and to help the public and journalists themselves better understand the biases present in media coverage.”
He emphasizes the importance of high-quality journalism in democratic societies and hopes the Detector will help improve transparency and accountability in news reporting.